
Why Questflow’s Benchmark Goes Beyond
Measuring What Matters — Performance, Pricing, and User Experience in Multi-Agent Image Workflows with Stablecoin-Powered Access


Introduction: Wrapping the Truth About AI Agents
The AI product boom has flooded app stores with image generators and content assistants, many promising state-of-the-art results with little technical effort. But a closer look reveals a different story.
From the App Store’s top-grossing “AI Art” apps to new multimodal tools bundled in productivity software, the common pattern is clear: most are wrappers. They rely on a single API (usually OpenAI, Midjourney, or SDXL), package it with preset templates, spend heavily on ads, and offer little real differentiation.
At Questflow, we believe users deserve more than templates. They deserve true agentic intelligence: composable, multi-model, cross-agent workflows that adapt to their creative needs, budget, and platform preferences.
To prove this, we didn’t just build another AI tool. We built an agent benchmarking framework that reflects real-world user priorities—not just model perplexity or latency—but cost-per-output, adaptability, and composability.
This blog explains why we built the Questflow Agent Benchmark, how it’s different from other benchmarks, what we’ve learned from early image generation workflows, and what it means for users, creators, and developers in the AI x Web3 space.
The Problem with Existing AI Benchmarks
Most benchmarks in the AI space focus on raw model metrics:
These are valuable for model researchers. But for everyday users and builders—especially those in creative or commercial workflows—they often miss the point.
What They Don’t Measure:
Cost per useful output (e.g., per image or tweet)
UI/UX complexity (how easy is it to get started?)
Workflow flexibility (can I use multiple tools?)
No-code compatibility
Stablecoin accessibility
Ecosystem composability
So we asked a different question:
💡 What if we benchmarked agents the way users experience them?
Introducing: Questflow Agent Benchmark
Questflow Agent Benchmark is a live, ongoing initiative to compare multi-agent workflows across a variety of tasks and platforms. It differs from model-level evaluation in four ways:

We started with image generation workflows—a high-demand, high-variance use case that blends creativity, multi-model potential, and clear user output.
Image Agents: Real-World Use Case
Most top-grossing image generation apps are simple wrappers for Midjourney, SDXL, or Runway. Questflow built something different:
Our Setup:
More leading models: GPT-4o, Midjourney, Stable Diffusion, Runway, Google Imagen, Flux, Deep Dream, Artbreeder
Unified prompt input: one user prompt, routed through orchestration logic
Multi-agent parallelism: models run in parallel or sequence depending on task
Stablecoin-powered: each image can be priced, purchased, and settled in USDC
Dynamic fallback and recovery: if one fails, another completes the task
This is not “select a model” UX. It’s “describe your vision, let agents decide.”
The Results: Cost, Quality, and Coverage
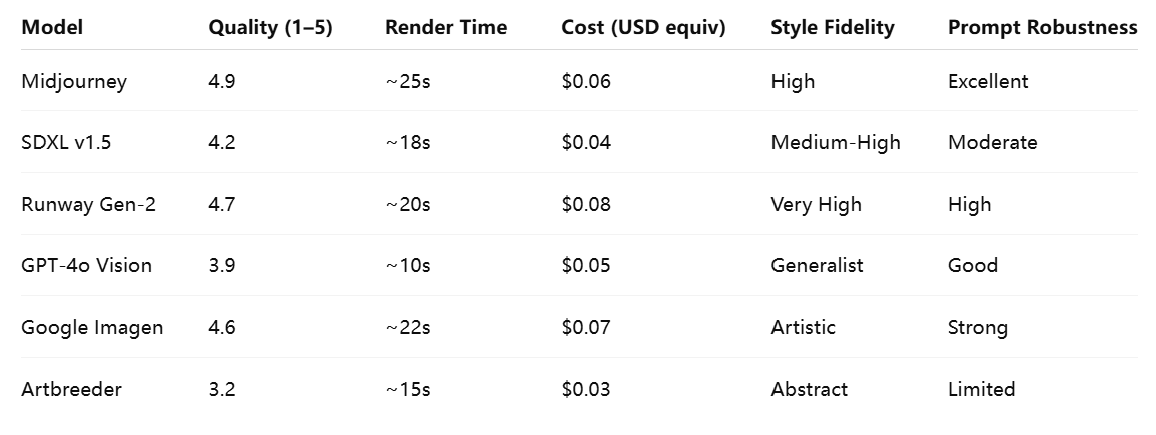
This is just one test case. The full benchmark includes dozens of prompt categories, from portraits to memes, anime to infographics.
Why Stablecoin-Powered Image Generation Matters
With stablecoin payments (like USDC) integrated:
Users can pay-per-image instead of monthly subscriptions.
Every agent can set its own price.
Developers can earn per agent usage.
UX becomes seamless for global users (no credit card required).
This unlocks the long-tail economy of creative AI.
Want a quick meme in under 10 seconds for $0.03?
Want an entire storyboard for your startup pitch for $1?
Want to pay in crypto with full provenance and programmable royalties?
With Questflow + USDC, this is already possible.
What Users Value: Benchmarking for Outcomes
We talked to over 100 users during this benchmark. Here’s what they care about most:

Interestingly, fewer than 10% mentioned “which model was used.”
They cared about results.
Beyond Image Gen: A Framework for All Agents
The benchmarking system we built doesn’t just apply to image generation.
Current Expansions:
Text Generation Agents: Blog summaries, brand tweets, Q&A bots
Video/Audio Tools: Clip generation, voiceover agents, podcast wrappers
Web3 Automators: Contract updaters, wallet trackers, airdrop handlers
DeFi Agents: Risk scanners, yield strategy optimizers, LP managers
All benchmarked by:
Cost per task
Task success rate
Prompt clarity needed
UX friction
How We Handle Benchmark Payments
One of our core insights is that users want to try things before they commit.
So we made every benchmark task:
Pay-per-use
Low-cost
Non-custodial
Built on USDC
Thanks to integrations with Circle, Base, and Coinbase Wallet, users can:
Sign in with wallet or email
Select agents
Run workflows
Pay per usage
See live results + leaderboard
We believe this will become the de facto standard for testing AI workflows—cheap, stable, onchain, and composable.
What Makes Questflow Different
Most agent or AI workflow platforms focus on:
Training larger models
Wrapping single APIs
Building SaaS dashboards
Questflow focuses on:
Composable agent swarms
MAOP orchestration (multi-agent, multi-model logic)
USDC-native incentives
Developer monetization
Our platform is not a wrapper. It’s a protocol layer. Think of it like Zapier meets Solidity meets GPT.
We let anyone:
Turn an API into an agent
Connect agents into workflows
Monetize and benchmark the outcome
And we benchmark it all—live, for the world to see.
What Comes Next: Leaderboards, Swarm Ratings, and User-Driven Rankings
We’re building:
Public dashboards of best-performing agents
Stablecoin bounties for top developers
Swarm recommendation engines based on success + cost
User reviews of agent combinations
Imagine a Yelp for agents—with pay-per-use preview flows.
Creators, developers, and users all benefit.
AI becomes transparent. And agents become measurable.
AI Benchmarking Reimagined for the Web3 World
At Questflow, our mission is to make intelligent services open, composable, and monetizable—for anyone.
That starts with honest benchmarking.
Not on token usage. But on outcome, cost, and usability.
We think the next billion users won’t care if your model is Claude, Gemini, or GPT.
They’ll care if it works, how fast, and how much.
That’s why we built the Questflow Agent Benchmark.
And we invite you to try it.